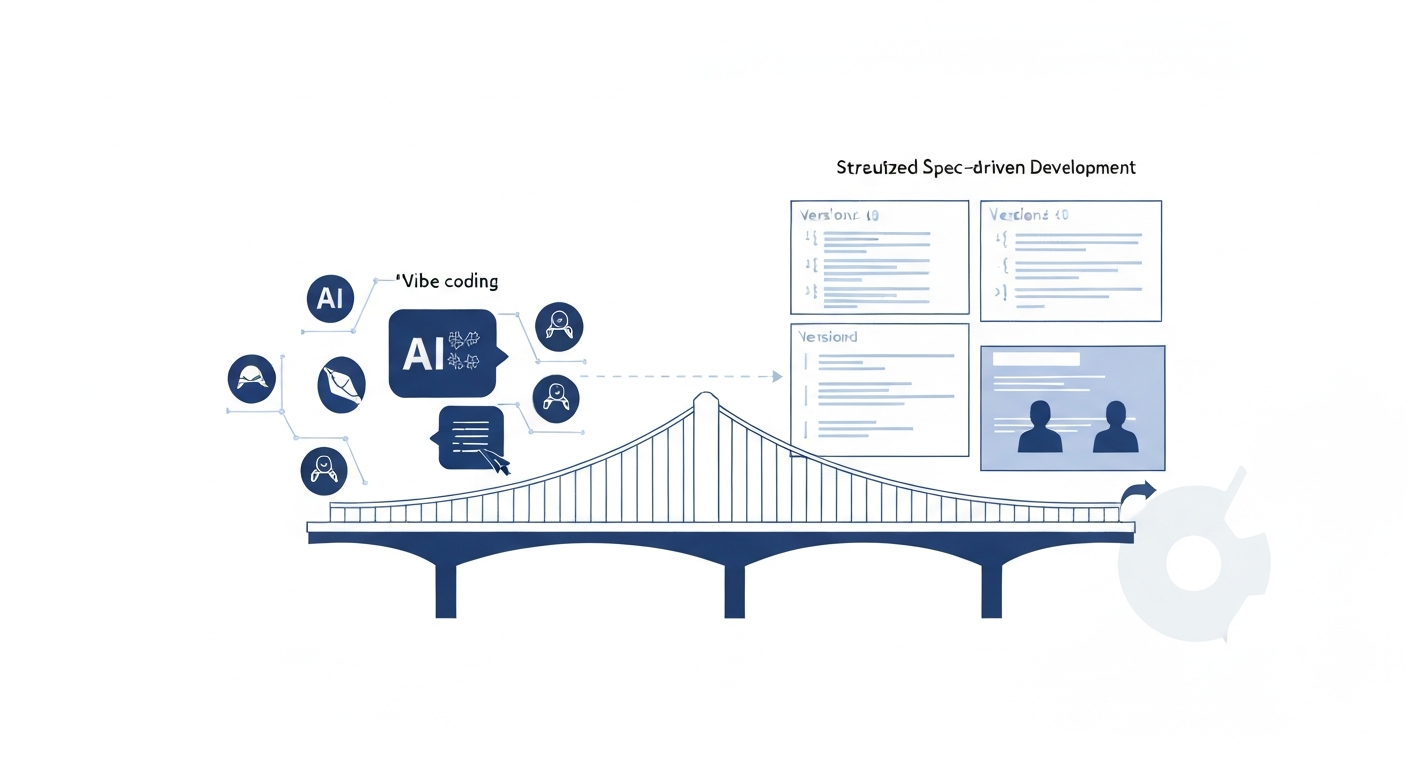
Вступ
ШІ-агенти швидко прискорюють інженерію даних, генеруючи трансформації, пайплайни, робочі процеси оркестрації, тести валідації та конфігурації інфраструктури на основі промптів. Однак корпоративні платформи даних давно працюють у фрагментованих системах, що належать різним командам і побудовані на різних технологіях. У міру незалежного розвитку цих систем організації все частіше стикаються з непослідовною бізнес-логікою, дублюванням реалізацій, складним аналізом впливу на подальші процеси та прихованими залежностями по всій платформі. Зростання "вайб-кодування" може ще більше посилити ці проблеми, оскільки більше операційного контексту, архітектурних рішень та бізнес-знань розсіюється по промптах, розмовах, згенерованому коду та роз'єднаних робочих процесах, замість того, щоб стати частиною самої системи.
Виклики "вайб-кодування" в інженерії даних
"Вайб-кодування" чудово працює для швидкої генерації ізольованих реалізацій. Однак промпти за своєю суттю є тимчасовими. Вони фіксують припущення інженера, бізнес-контекст, логіку реалізації та системні знання лише для конкретної розмови та моменту часу. На практиці, щоб змусити системи, згенеровані ШІ, працювати, часто потрібно набагато більше, ніж простий промпт. Інженери постійно надають фонову інформацію, архітектурні рішення, бізнес-правила, припущення щодо схем, залежності, операційні обмеження, історію налагодження та рекомендації щодо реалізації протягом усього процесу розробки. Ці контексти стають справжніми операційними знаннями, що стоять за розробкою за допомогою ШІ.
Однак у більшості робочих процесів "вайб-кодування" ця інформація залишається розсіяною по промптах, розмовах, тікетах Jira, документації, історії чатів, згенерованому коду та роз'єднаних робочих процесах, замість того, щоб стати частиною самої системи. Це створює серйозну проблему для корпоративної інженерії даних, оскільки сучасні платформи даних природно фрагментовані по багатьох взаємопов'язаних системах. У міру того, як більше логіки та контексту вбудовується в промпти та згенеровані реалізації, організації поступово втрачають видимість архітектурного задуму, подальших залежностей, припущень валідації, операційної поведінки та бізнес-контексту за реалізаціями. З часом сама система більше не містить повного обґрунтування того, як вона була побудована. Критичний бізнес-контекст, архітектурні припущення та операційні знання все ще значною мірою існують у людських судженнях та розрізнених розмовах, а не всередині самої платформи.
"Вайб-кодування" значно прискорює реалізацію, але з системної точки зору загальна ефективність інженерії не покращується пропорційно, оскільки значна частина життєвого циклу розробки все ще залежить від людської валідації, доменних знань, координації та прийняття рішень. Важливо, що промпти не є природно ітерованими інженерними артефактами. Корпоративні системи постійно розвиваються протягом релізів, змін схем, оновлень бізнес-логіки та подальших залежностей. Команди неодноразово переглядають та вдосконалюють системи з часом, але промпти оптимізовані для швидкої локальної генерації, а не для довгострокової еволюції системи. Їх важко послідовно версіонувати, систематично валідувати, повторно використовувати між командами, координувати через робочі процеси CI/CD та поступово розвивати з часом. Навіть той самий промпт може не завжди надійно генерувати ту саму реалізацію з іншим контекстом у майбутньому.
Специфікаційно-орієнтована розробка (SDD) як рішення
Саме тут SDD починає займати центральне місце в інженерії даних за допомогою ШІ. Замість того, щоб залишати операційні знання розсіяними по промптах та розмовах, SDD інтегрує бізнес-контекст, логіку валідації, поведінку трансформації, вимоги до оркестрації та робочі процеси реалізації безпосередньо у виконувані специфікації, які стають частиною самої системи. Система тепер має постійну пам'ять про те, як вона була розроблена, чому були прийняті певні рішення та як різні компоненти пов'язані по всій платформі. Це дозволяє командам та ШІ-агентам надійніше ітерувати системи з часом, зменшуючи фрагментацію в дедалі більш розподілених середовищах даних.
У SDD системи будуються навколо виконуваних специфікацій, а не лише вільно скоординованих промптів та реалізацій. Замість того, щоб розглядати специфікації як пасивну документацію, написану після розробки, SDD розглядає їх як операційні контракти, які безпосередньо керують генерацією коду, валідацією, тестуванням, оркестрацією та робочими процесами розгортання. Багато в чому SDD розширює ідеї Infrastructure-as-Code та GitOps на інженерію за допомогою ШІ. Специфікації поєднують декларативні визначення системи з виконуваними робочими процесами реалізації. Декларативний шар надає системний контекст, схеми, залежності, обмеження та операційні вимоги, тоді як орієнтовані на робочий процес інструкції керують ШІ-агентами щодо того, як послідовно реалізовувати та розвивати систему.
Після того, як ці контексти, правила та шаблони реалізації перетворюються на постійні та версіоновані контракти, що зберігаються в репозиторіях та інтегровані в робочі процеси CI/CD, система стає значно більш ітерованою та керованою з часом. Ці специфікації ефективно стають довгостроковою системною пам'яттю як для людей, так і для ШІ-агентів, дозволяючи системам послідовно розвиватися протягом релізів, команд та дедалі більше робочих процесів розробки за допомогою ШІ. Структура специфікацій значною мірою залежить від типу систем та робочих процесів, що реалізуються. Однак специфікаційно-орієнтовані системи часто починаються з фундаментальної "конституції", яка визначає загальнопроєктні принципи та обмеження, що повинні залишатися послідовними по всій платформі, такі як технологічні стандарти, угоди про іменування, архітектурні правила, політики управління та основні системні вимоги. На цій основі кілька шарів специфікацій служать різним операційним цілям протягом життєвого циклу розробки:
- специфікації схем визначають структурну сумісність
- специфікації трансформацій визначають бізнес-логіку
- специфікації валідації визначають правила якості
- специфікації оркестрації визначають поведінку виконання
- семантичні специфікації визначають спільні бізнес-визначення
- специфікації робочих процесів ШІ визначають багаторазові інструкції з реалізації для агентів кодування
Спрощена специфікація може виглядати так: pipeline_spec: source: system: mysql table: order transformation: logic: - load_strategy: scd2 target: platform: snowflake table: dim_order validation: primary_key: order_id. Додаткові файли робочих процесів можуть надавати багаторазові інструкції з реалізації для агентів кодування, наприклад: "Згенерувати код Python для завантаження даних клієнтів Salesforce", "Згенерувати моделі DBT, що реалізують логіку SCD типу 2", "Згенерувати робочі процеси Airflow для погодинного виконання", "Згенерувати тести валідації для подальшої сумісності". Ці специфікаційні документи часто підтримуються як операційні артефакти на основі Markdown, що генеруються та вдосконалюються за допомогою робочих процесів ШІ. Інженери можуть ітеративно оновлювати специфікації, надавати додатковий бізнес-контекст та співпрацювати з агентами кодування для покращення логіки реалізації, робочих процесів та інструкцій промптів з часом. Порівняно з традиційними процесами документування, генерація специфікацій за допомогою ШІ значно швидша та адаптивніша. Важлива зміна полягає не просто в кращій документації. Специфікації стають багаторазовим операційним контекстом, що дозволяє системам послідовно розвиватися протягом релізів, команд та робочих процесів за допомогою ШІ. Архітектурний задум, бізнес-припущення та логіка реалізації більше не зникають у тимчасових промптах та роз'єднаних реалізаціях, а натомість стають постійними системними знаннями, інтегрованими безпосередньо в життєвий цикл розробки.
Чому SDD особливо підходить для інженерії даних
SDD теоретично може бути застосована в багатьох областях розробки програмного забезпечення, але інженерія даних особливо добре підходить для цієї моделі через природу сучасних платформ даних. Корпоративні системи даних природно охоплюють багато взаємопов'язаних технологій та шарів. Інженери даних регулярно працюють з довгими технологічними стеками та розподіленими системами, де одна зміна на вищому рівні може вплинути на багатьох споживачів на нижчому рівні. Корпоративні платформи даних також підтримують багато різних команд та додатків у фрагментованих середовищах. У міру незалежного розвитку систем розуміння повного подальшого впливу зміни схеми або бізнес-логіки на вищому рівні стає дедалі складнішим. Здавалося б, невелика модифікація може непомітно порушити подальші пайплайни, дашборди, API, семантичні моделі або робочі процеси машинного навчання по всій платформі.
SDD може вирішити цю фрагментацію, запровадивши спільні та версіоновані операційні контракти між системами. Оскільки схеми, залежності, правила валідації, логіка трансформації та поведінка оркестрації явно визначені в специфікаціях, команди та ШІ-агенти отримують набагато кращу видимість того, як системи пов'язані та як зміни поширюються по всій платформі. Крім того, метою інженерії даних є не просто швидке створення пайплайнів. Команди також повинні оптимізувати стабільність системи, масштабованість, послідовність, ремонтопридатність, операційну надійність та вартість інфраструктури. Це вимагає значної роботи з системного та архітектурного проектування від інженерів. Команди повинні ретельно визначати технологічний стек, створювати схеми, шаблони трансформації, поведінку оркестрації, правила валідації, стратегії зберігання та вимоги до подальшої сумісності по всій платформі. Однак, як тільки ці архітектурні та операційні шаблони встановлені, значна частина роботи з реалізації стає дуже повторюваною та стандартизованою. Наприклад, після визначення багаторазового шаблону завантаження та трансформації для даних клієнтів Salesforce, додавання нової таблиці може вимагати лише додавання іншого визначення таблиці до специфікації, тоді як решта реалізації може бути автоматично згенерована за допомогою існуючих специфікацій та робочих процесів, які дотримуються того ж операційного шаблону. З цієї специфікації агенти кодування можуть генерувати нові пайплайни даних, дотримуючись того ж керованого шаблону реалізації по всій платформі. Це поєднання архітектурного проектування, керованого людиною, та високоповторюваних робочих процесів реалізації робить інженерію даних особливо придатною для SDD. Багато в чому інженерія даних завжди рухалася до вищих рівнів автоматизації, від фреймворків ETL та пайплайнів, керованих метаданими, до IaC та декларативних систем оркестрації. SDD представляє ще один крок у цій еволюції, поєднуючи генерацію ШІ на основі промптів з детермінованими та версіонованими операційними контрактами. Замість того, щоб повністю покладатися на тимчасові розмовні промпти або жорсткі шаблонні системи, SDD вводить проміжний шар, де багаторазові специфікації забезпечують структуру, координацію, валідацію та постійну системну пам'ять для розробки за допомогою ШІ.
Трансформація інженерії даних за допомогою SDD
SDD вводить набагато вищий рівень автоматизації в корпоративну інженерію даних, одночасно допомагаючи зменшити проблеми фрагментації, з якими дедалі частіше стикаються сучасні платформи даних. Оскільки схеми, бізнес-правила, поведінка трансформації, вимоги до оркестрації, логіка валідації та подальші залежності явно визначені в багаторазових специфікаціях, агенти кодування можуть послідовно генерувати та розвивати великі частини реалізації по всій платформі. Замість того, щоб неодноразово перебудовувати пайплайни та робочі процеси з тимчасових промптів та роз'єднаного контексту, команди можуть ітерувати системи через спільні операційні контракти та багаторазові шаблони реалізації. Це значно покращує послідовність, відстежуваність та координацію в розподілених середовищах. Еволюцією схем стає легше керувати, подальший вплив стає більш видимим, а системи можуть розвиватися поступово, а не через роз'єднані генерації реалізацій.
Водночас, людські інженери все ще залишаються важливими в життєвому циклі розробки. Хоча ШІ-агенти можуть автоматизувати значні частини роботи з реалізації, людське судження все ще є критично важливим для визначення бізнес-логіки, проектування архітектур, управління компромісами, валідації коректності та координації еволюції системи в організаціях. У міру того, як все більше роботи з реалізації стає згенерованою ШІ, роль інженерії даних також починає змінюватися. Інженери витрачають менше часу на написання повторюваних пайплайнів та логіки оркестрації, і більше часу на визначення специфікацій, проектування багаторазових операційних шаблонів, управління правилами валідації та координацію бізнес-контексту між системами. Це також може поступово зменшити деякі традиційні межі між різними командами інженерії даних. Оскільки реалізація стає дедалі більш стандартизованою та автоматизованою за допомогою ШІ через спільні специфікації, організації можуть менше покладатися на високоізольовані команди реалізації, специфічні для платформи, і більше на спільні операційні контракти та багаторазові системні шаблони. Зрештою, SDD переводить інженерію даних на більш специфікаційно-орієнтовану та системно-орієнтовану модель, де люди зосереджуються на намірах, архітектурі та бізнес-координації, тоді як ШІ-агенти дедалі більше займаються реалізацією, тестуванням та операційною генерацією в масштабі.
Що це означає для розробників
SDD змінює роль інженерів даних, переносячи фокус з рутинного кодування на визначення специфікацій, проектування багаторазових операційних шаблонів та координацію бізнес-контексту. Це дозволяє їм зосередитися на архітектурі та бізнес-логіці, тоді як ШІ-агенти автоматизують реалізацію та тестування.
Ключові факти
-
ШІ-агенти прискорюють інженерію даних, генеруючи трансформації, пайплайни та конфігурації.
-
"Вайб-кодування" (генерація на основі промптів) посилює фрагментацію та розсіювання контексту, оскільки промпти є тимчасовими.
-
Специфікаційно-орієнтована розробка (SDD) перетворює правила та логіку на виконувані, версіоновані специфікації, що стають частиною системи.
-
SDD діє як постійна операційна пам'ять, дозволяючи системам послідовно розвиватися та зменшуючи фрагментацію.
-
Інженерія даних особливо підходить для SDD завдяки своїй природній фрагментації та потребі в стандартизованих, повторюваних шаблонах.
Джерела
Джерело
VenturebeatShuhua Xu
Vibe coding can build your pipeline. It can't explain it six months later15 червня 2026 · оновлено 15 червня 2026
Попередні статті
Ринок хмарних обчислень у сфері охорони здоров'я досягне $169,34 млрд до 2031 року
Глобальний ринок хмарних обчислень для охорони здоров'я прогнозується зрости до $169,34 млрд до 2031 року зі значним річним темпом зростання 18,0%. Цей ріст зумовлений цифровою трансформацією, потребою в сумісності та моделями догляду, орієнтованими на дані.

Ринок центрів обробки даних зростає завдяки хмарним технологіям та ШІ
Глобальний ринок центрів обробки даних демонструє значне зростання, прогнозується збільшення до $506.09 млрд до 2034 року. Цей бум зумовлений стрімким розвитком хмарних обчислень, штучного інтелекту, IoT та цифрової трансформації, що робить ЦОДи критично важливою інфраструктурою сучасної цифрової економіки.
Kimi AI: Агентний AI-простір для кодування, контенту та аналізу даних
Kimi AI від Moonshot AI — це мультимодальна платформа, що функціонує як агентний AI-простір, об'єднуючи робочі процеси кодування, створення контенту, аналізу даних та підвищення продуктивності в єдиному середовищі.
Наступні статті

Databricks представляє нові можливості Lakeflow для агентної інженерії даних
Databricks оголосила про значне оновлення Lakeflow, уніфікованої платформи для інженерії даних. Нові функції включають візуальний дизайнер без коду, агент для автоматизації операцій, розширені конектори, високопродуктивне завантаження подій та можливості оркестрації.
Інженерія даних переосмислює лідерство на локальному ринку: досвід Columbus Marketing Experts
Фірма Columbus Marketing Experts з Огайо доводить, що не бюджет, а інженерний підхід до даних та оптимізації пошуку дозволяє локальним бізнесам перемагати національних гігантів, створюючи нову модель домінування на ринку.

Губернатор Техасу закликає до регулювання центрів обробки даних
Губернатор Техасу Грег Ебботт закликав до регулювання центрів обробки даних, щоб оператори несли більше витрат на своє зростання, на тлі тиску щодо енергоспоживання, використання води та місцевої опозиції.