Початок шляху в інженерії даних
Автор, який переходить з аналітика даних в інженера даних, розпочав свій шлях з практичного завдання: створення першого ETL-конвеєра. Мотивацією для цього стало бажання не лише вивчати теорію, а й побудувати щось реальне, що працює з реальними даними. Для цього він обрав GitHub API та Python, відмовившись від готових навчальних посібників на користь самостійної розробки.
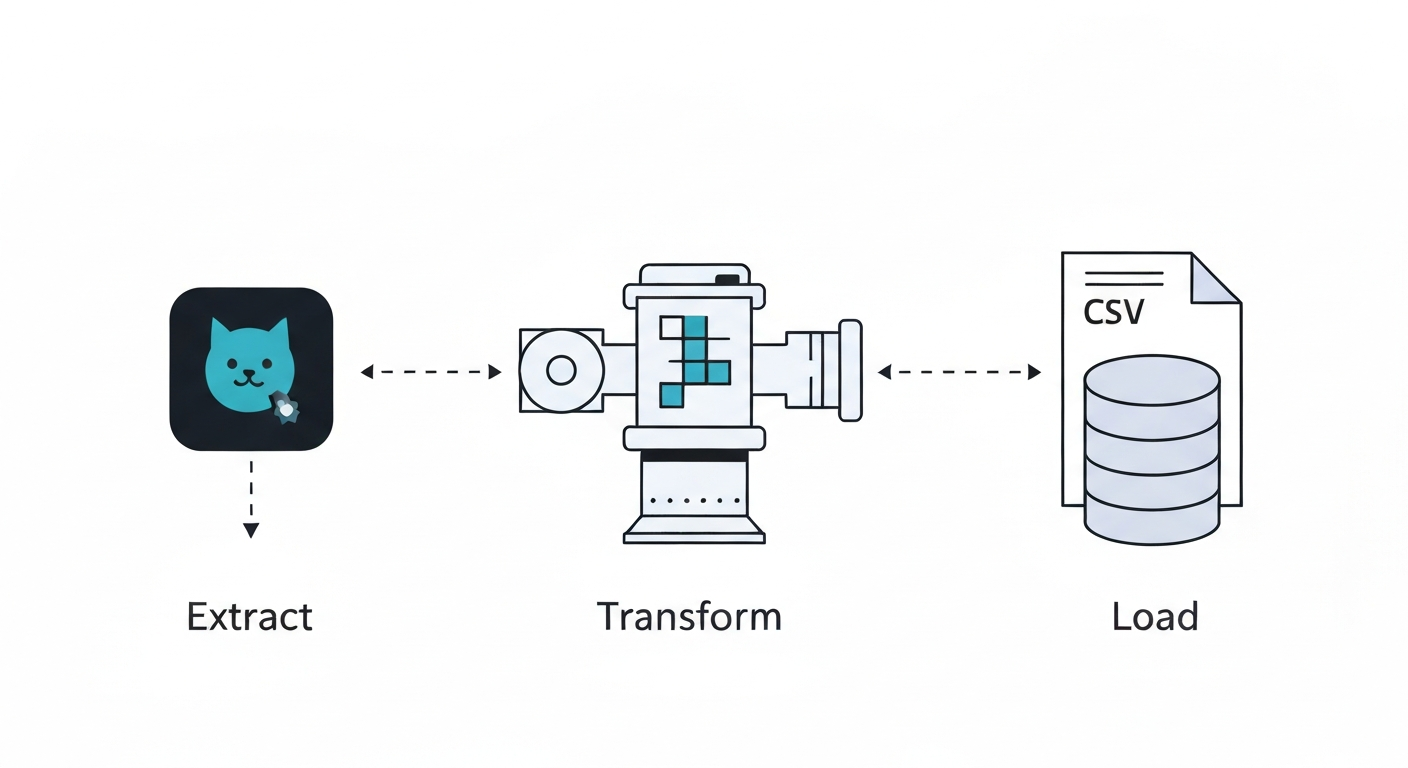
Що таке ETL?
ETL розшифровується як Extract, Transform, Load (Вилучення, Трансформація, Завантаження). Це один з фундаментальних концептів в інженерії даних.
- Вилучення (Extract): Процес отримання сирих даних з джерела, такого як API, база даних, вебсайт або файл.
- Трансформація (Transform): Очищення та формування даних, що включає видалення некоректних рядків, додавання нових стовпців або реструктуризацію для підвищення їх корисності.
- Завантаження (Load): Збереження очищених даних у цільове сховище, наприклад, базу даних, сховище даних або простий CSV-файл.
Ці три кроки, виконані послідовно, складають конвеєр даних. Інші інструменти, такі як Airflow, Spark або Databricks, є більш складними способами виконання цих самих завдань у масштабі. Для свого першого проєкту автор обрав чистий Python без інструментів оркестрації.
Створений конвеєр
Автор розробив ETL-конвеєр, який вилучав дані з GitHub API. Зокрема, він шукав найпопулярніші (за кількістю зірок) репозиторії Python, створені за останні 30 днів. Потім дані були очищені, до них додано новий стовпець, а результат збережено у CSV-файл.
Крок 1: Вилучення даних
Для вилучення даних використовувався GitHub API, який дозволяє програмно запитувати дані. GitHub надає безкоштовний публічний API.
Автор використав бібліотеку requests у Python для взаємодії з API. Запит надсилався на URL https://api.github.com/search/repositories з параметрами, що вказували на пошук репозиторіїв Python, створених після 22 квітня 2025 року, відсортованих за зірками у спадному порядку, з обмеженням у 30 результатів. Метод .json() перетворював відповідь API на словник Python.
Успішна відповідь API позначається статусом 200. Отриманий словник містив ключі total_count, incomplete_results та items, де items містив самі дані репозиторіїв. Наприклад, було виявлено 9228201 відповідних репозиторіїв, з яких було повернуто 30. Перший репозиторій у результатах мав назву "skills" від Anthropic, 139136 зірок та був написаний на Python.
Крок 2: Трансформація даних
Отримані дані були списком вкладених словників. Етап трансформації полягав у формуванні цих сирих даних.
Автор вибрав потрібні поля (name, owner, stars, forks, language, description, url, created_at) та завантажив їх у DataFrame Pandas.
Було виконано три трансформації:
- Видалено рядки, де відсутній опис (
description). - Додано стовпець
viral(вірусний) для репозиторіїв з понад 50 000 зірок. - Відсортовано дані за кількістю зірок у спадному порядку.
Після очищення з 30 початкових репозиторіїв залишилося 29, оскільки один репозиторій не мав опису.
Крок 3: Завантаження даних
На останньому етапі очищені дані були збережені. Автор обрав простий спосіб, завантаживши їх у CSV-файл з назвою github_trending_repos.csv.
У файл було завантажено 29 репозиторіїв. Результатом став чистий електронний табличний файл з 29 рядками та 9 стовпцями.
Висновки та подальші кроки
Досвід створення цього конвеєра змінив сприйняття автора щодо роботи з даними. Він усвідомив, що може самостійно вилучати живі дані з API та створювати власні набори даних, а не лише споживати вже існуючі. Це підкреслило важливість практичного будівництва над теоретичним вивченням.
Наступні кроки включатимуть підвищення надійності конвеєра, планування його щоденного запуску, зберігання результатів у базі даних SQLite замість CSV та відстеження тенденцій репозиторіїв з часом. Зрештою, планується оркеструвати весь процес за допомогою Airflow.
Що це означає для розробників
Цей досвід показує розробникам, що вони можуть самостійно створювати набори даних, вилучаючи живі дані з API, а не обмежуватися вже існуючими. Він підкреслює, що практичне створення ETL-конвеєрів допомагає краще зрозуміти фундаментальні концепції інженерії даних, ніж лише теоретичне вивчення.
Ключові факти
-
Автор-початківець створив свій перший ETL-конвеєр, використовуючи Python.
-
ETL означає Extract (Вилучення), Transform (Трансформація), Load (Завантаження) і є фундаментальним концептом в інженерії даних.
-
Конвеєр вилучав дані про найпопулярніші Python-репозиторії з GitHub API.
-
Для вилучення використовувалася бібліотека
requests, для трансформації —pandas. -
Дані були очищені, додано стовпець "viral" для репозиторіїв з понад 50 000 зірок.
Джерела
Джерело
Towards Data ScienceIbrahim Salami
I Built My First ETL Pipeline as a Complete Beginner. Here’s How.25 травня 2026 · оновлено 25 травня 2026
Попередні статті

New Relic представила AI Coding Observability для розробки з ШІ
New Relic анонсувала відкриту функцію AI Coding Observability, яка надає інженерним командам видимість у використання помічників для кодування з ШІ. Вона покликана усунути прогалини в моніторингу, що виникають при широкому впровадженні таких інструментів, відстежуючи витрати, продуктивність, безпеку та відповідність.

Штучний інтелект у розробці програмного забезпечення: інструменти, ризики та еволюція ролей
Штучний інтелект трансформує розробку програмного забезпечення, підвищуючи ефективність та змінюючи ролі розробників. Матеріал розглядає, як ШІ допомагає у повсякденній роботі, які інструменти доступні, які ризики існують та які навички стають ключовими для фахівців.

Новий підхід до паралельного програмування: дані як активні учасники обчислень
Дослідження Франкена пропонує дата-орієнтовану парадигму для паралельного програмування, де дані активно виконують обчислення та взаємодіють локально, зменшуючи потребу в явній координації процесів.
Наступні статті

Втрата даних через автономний ШІ в DevOps: Нові загрози та стратегії захисту
Автономні агенти ШІ прискорюють розробку програмного забезпечення, але водночас скорочують час, за який помилка може перетворитися на катастрофу. Традиційні заходи безпеки виявляються неефективними проти цієї нової загрози, що вимагає переосмислення стратегій захисту даних.

Elastic представляє нові функції спостережуваності для Kubernetes
Elastic додала нові функції спостережуваності для Kubernetes, що допомагають SRE-інженерам діагностувати та вирішувати інциденти, централізуючи дані журналів, метрик і трасування.

Федеральний суд скасував збір у $100 000 за візу H-1B: Засновник техкомпанії про вплив на індійських студентів
Засновник техкомпанії Зак Вілсон, колишній співробітник Meta та Netflix, висловив гордість за рішення федерального суду США скасувати збір у $100 000 за візи H-1B, запроваджений адміністрацією Трампа. Він зазначив, що цей збір ускладнював працевлаштування індійських студентів у США.