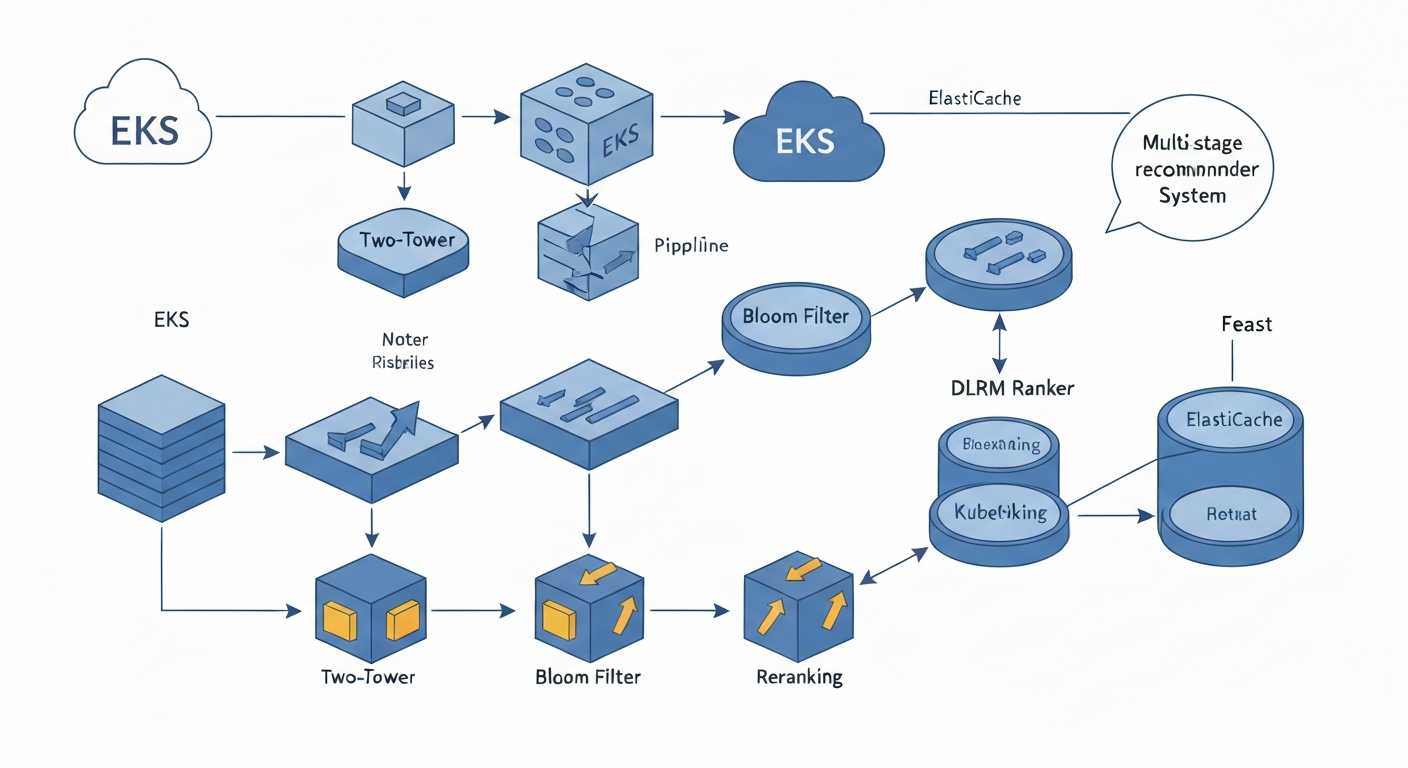
Архітектура багатоетапної системи рекомендацій
Описана багатоетапна мультимодальна рекомендаційна система розроблена для електронної комерції та розгорнута на Amazon Elastic Kubernetes Service (EKS). Вона призначена для масштабування, адаптації майже в реальному часі та надійної роботи в хмарі. Система складається з чотирьох основних етапів:
- Генерація кандидатів: Модель Two-Tower генерує початковий набір кандидатів.
- Фільтрація: Фільтр Блума тимчасово приховує елементи, з якими користувач нещодавно взаємодіяв.
- Ранжування: Ранжувальник DLRM оцінює елементи, що залишилися, використовуючи функції користувача, елемента та контексту.
- Переранжування: Фінальний етап переранжування впорядковує та вибирає елементи з цих оцінок для формування остаточних рекомендацій.
Моделі використовують як табличні колаборативні функції, так і попередньо обчислені вбудовування зображень CLIP та текстові вбудовування Sentence-BERT. У моделі пошуку ці попередньо навчені вбудовування подаються в «вежу кандидатів» разом з вивченими функціями елементів, забезпечуючи як семантичні сигнали на основі контенту, так і колаборативні сигнали. У ранжувальнику DLRM попередньо навчені вбудовування зображень та тексту беруть участь у шарі взаємодії точкового добутку, доповнюючи колаборативні та контекстуальні сигнали.
Обґрунтування дизайну та ключові компоненти
Цей дизайн був обраний для платформи електронної комерції, яка потребує рекомендацій продуктів одразу після входу користувачів на домашню сторінку. Система повинна обслуговувати як зареєстрованих, так і анонімних відвідувачів, адаптуючись до контексту запиту (тип пристрою, час доби, день тижня). Багатоетапний дизайн вирішує проблему масштабування каталогу до мільйонів елементів, використовуючи легкий етап пошуку для швидкого отримання кандидатів та більш «важкий» етап ранжування для їх оцінки.
Для підтримки актуальності рекомендаційних моделей без щоденної повної перебудови, визначено два конвеєри Kubeflow: один для повного навчання та розгортання, інший для щоденного доналаштування.
Ключові компоненти системи включають:
- Kubeflow Pipelines: Керує повним робочим процесом навчання та щоденним доналаштуванням.
- NVIDIA Merlin: Обробляє прискорену на GPU інженерію функцій, попередню обробку та навчання моделей.
- Triton Inference Server: Розміщує багатоетапний граф обслуговування як єдину ансамблеву модель.
- FAISS: Використовується як індекс наближених найближчих сусідів для пошуку кандидатів.
- Feast: Керує функціями користувачів та елементів.
- ElastiCache for Valkey (Redis): Підтримує онлайн-сховище функцій, керує фільтрами Блума для кожного користувача та зберігає інформацію про популярність елементів.
- Amazon Athena (з S3 та Glue): Підтримує офлайн-сховище функцій.
- Amazon Elastic Kubernetes Service (EKS): Запускає контейнеризовані робочі процеси машинного навчання та масштабує обчислювальні ресурси.
Дані для навчання походять з модифікованої версії генератора взаємодій AWS Retail Demo Store, що включає 300 000 користувачів, 2 465 товарів та 13 мільйонів взаємодій за 14 днів.
Конвеєри навчання та розгортання
Конвеєр повного навчання та розгортання
Цей конвеєр обробляє початкове копіювання даних, попередню обробку, навчання моделей, індексацію FAISS та розгортання Triton Inference Server.
- Копіювання даних: Копіювання вхідних даних (взаємодії, таблиці функцій, зображення продуктів, попередньо навчені моделі CLIP та Sentence-BERT) з S3.
- Попередня обробка: Об'єднання даних взаємодії з таблицями функцій, визначення та застосування трьох робочих процесів NVTabular (для користувачів, елементів, контексту). Симуляція умов холодного старту під час навчання шляхом маскування 5% рядків даних. Кодування зображень продуктів за допомогою OpenAI CLIP та описів за допомогою Sentence-BERT, зменшення їх до 64-вимірних векторів PCA. Підготовка офлайн та онлайн артефактів функцій, обчислення глобальної та категорійної популярності.
- Навчання моделі пошуку: Модель Two-Tower навчається на функціях користувача та елемента. Після навчання кодер кандидатів запускається для обчислення вбудовувань елементів, які використовуються для побудови індексу FAISS.
- Навчання моделі ранжування: Ранжувальник DLRM навчається на тих самих даних взаємодії, але з розширеним набором функцій, включаючи контекстні функції часу запиту (наприклад, тип пристрою, циклічний час доби).
- Підготовка та розгортання моделі: Збірка артефактів для Triton (збережені «вежа запитів», ранжувальник DLRM, моделі трансформації NVTabular, індекс FAISS, таблиці пошуку мультимодальних вбудовувань). Розгортання Triton Inference Server на EKS за допомогою Helm-чарту.
Конвеєр безперервного доналаштування
Цей конвеєр забезпечує щоденні оновлення моделей.
- Копіювання інкрементальних даних: Копіювання останніх даних взаємодії з Amazon S3 разом з меншим набором старих взаємодій для ширшого поведінкового контексту.
- Попередня обробка даних: Об'єднання історичних функцій користувача та елемента з новими даними взаємодії, трансформація за допомогою раніше підігнаних робочих процесів NVTabular.
- Доналаштування моделей: Оновлення «вежі запитів» та ранжувальника DLRM. «Вежа кандидатів» заморожується, щоб адаптувати модель до недавньої поведінки користувача, зберігаючи при цьому вбудовування елементів. Ранжувальник DLRM навчається з меншою швидкістю навчання та меншою кількістю епох.
- Просування доналаштованих моделей: Triton завантажує нові моделі у фоновому режимі, обслуговуючи поточні запити на існуючих версіях, а потім виконує «гарячу заміну» на нові версії.
Обробка запитів та оптимізації
Triton Inference Server обробляє запити через 14 моделей, організованих в ансамбль.
- Підготовка контексту та функцій користувача: Запити надходять з ID користувача та опціональним типом пристрою/часовою міткою.
context_preprocessorзаповнює пропущені значення.feast_user_lookupотримує функції користувача з онлайн-сховища,nvt_user_transformїх трансформує, аquery_towerгенерує вбудовування користувача дляfaiss_retrieval. - Обробка холодного старту користувача: Якщо ID користувача не знайдено,
feast_user_lookupвикористовує значення за замовчуванням, якіnvt_user_transformвідображає в OOV індекси. Ранжувальник DLRM може персоналізувати порядок кандидатів, використовуючи доступний контекст. - Фільтрація переглянутих елементів: Фільтр Блума в ElastiCache for Valkey перевіряє ID кандидатів, виключаючи вже переглянуті елементи.
- Ранжування та впорядкування: Модель
unroll_featuresрозширює функції користувача та контексту.dlrm_rankingоцінює кандидатів.softmax_samplingповертає топ-K кандидатів за спаданням оцінки або використовує зважену вибірку для різноманітності.item_id_decoderвідображає ID кандидатів назад до оригінальних ID елементів.
Оптимізація затримки пошуку функцій елементів
Профілювання сервера показало, що feast_item_lookup був вузьким місцем, споживаючи 195 мс (52% загальної затримки). Для вирішення цієї проблеми виклики Feast для функцій елементів були замінені кешем NumPy-масивів у пам'яті. Усі функції елементів завантажуються один раз при ініціалізації feast_item_lookup і зберігаються в пам'яті. Це призвело до покращення затримки feast_item_lookup на 99.7%, загальної затримки на 54% та пропускної здатності на 310%. Компроміс полягає в тому, що кешовані функції оновлюються лише при перезапуску Triton.
Автомасштабування та валідація
Автомасштабування Triton Inference Server на EKS
Triton Inference Server автомасштабується за допомогою Kubernetes Horizontal Pod Autoscaler (HPA) на основі власної метрики — середнього часу очікування запиту в черзі. Коли ця затримка перевищує цільове значення, HPA масштабує розгортання Triton. Якщо новий под Triton не може бути запланований через відсутність потужності GPU-вузла, Karpenter надає новий GPU-вузол.
Валідація рекомендацій
- Контекстуальні рекомендації: Тести показали, що рекомендації для невідомих користувачів змінюються залежно від контексту (тип пристрою, час запиту). Для існуючих користувачів ефект контексту був менш вираженим, хоча вихідні оцінки змінювалися.
- Фільтрація переглянутих елементів: Клікнуті елементи були виключені з подальших рекомендацій фільтром Блума.
- Оновлення рекомендацій майже в реальному часі: Повторні взаємодії з елементами однієї категорії (наприклад, меблі) зміщують
top_categoryкористувача, що призводить до оновлення рекомендацій, які відображають цей новий інтерес.
Обмеження та майбутні напрямки
Поточна архітектура використовує контекст запиту (тип пристрою, часові функції) лише ранжувальником. Майбутні напрямки включають додавання контекстних функцій до «вежі запитів» для контекстно-орієнтованого пошуку. Також планується замінити поточну «вежу запитів» на сесійний кодер для більш точного моделювання короткострокової поведінки користувача.
Що це означає для розробників
Ця архітектура демонструє практичні патерни для розробників, які створюють або масштабують рекомендаційні системи, зокрема використання багатоетапного підходу, мультимодальних функцій, конвеєрів MLOps для навчання та доналаштування, а також оптимізації продуктивності, такі як кешування в пам'яті та автомасштабування.
Ключові факти
-
Система є багатоетапною та мультимодальною, розгорнутою на Amazon EKS для електронної комерції.
-
Використовує Two-Tower модель для пошуку, фільтр Блума для приховування переглянутих елементів та DLRM ранжувальник.
-
Включає конвеєри Kubeflow для повного навчання та щоденного доналаштування моделей.
-
Оптимізація затримки за допомогою кешування функцій елементів у пам'яті покращила продуктивність на 54% end-to-end.
-
Автомасштабування реалізовано за допомогою Kubernetes HPA та Karpenter на основі часу очікування запиту.
Джерела
Джерело
Towards Data ScienceMustapha Momoh
Deploying a Multistage Multimodal Recommender System on Amazon Elastic Kubernetes Service19 травня 2026 · оновлено 21 травня 2026
Попередні статті

Ринок медичного кодування: Прогнозоване зростання до $106 млрд до 2034 року на тлі цифровізації та ШІ
Глобальний ринок медичного кодування, що оцінювався у $44.12 млрд у 2025 році, за прогнозами, досягне $106.09 млрд до 2034 року. Цей ріст зумовлений систематичною трансляцією медичних даних у стандартизовані коди, що є основою для взаємодії даних та відшкодування витрат у охороні здоров'я.

Anthropic укладає угоду зі SpaceX щодо обчислювальних ресурсів та представляє функцію «мрій» для ШІ
Anthropic уклала угоду зі SpaceX про використання обчислювальних потужностей центру Colossus 1, отримавши 300 МВт нової потужності. Компанія також представила функцію «мрій» для ШІ та подвоїла ліміти Claude Code для платних планів.

Новий звіт пропонує дорожню карту для інтеграції даних та обчислень у шкільну освіту K-12
Новий звіт Національних академій наук, інженерії та медицини зазначає, що інтеграція даних та обчислень у шкільну освіту K-12 є критично важливою, але відбувається нерівномірно. Документ пропонує дорожню карту з 14 рекомендаціями для послідовного впровадження цих знань.
Наступні статті

BigID розширює DSPM на файли Markdown, усуваючи критичний пробіл у безпеці даних
BigID оголосила про підтримку сканування та класифікації файлів Markdown (.md), ставши єдиним рішенням DSPM, здатним виявляти та захищати конфіденційні дані в інструкціях для ШІ, які є невидимими для традиційних інструментів безпеки.

Vibe Coding: Революція у розробці та нові виклики для кібербезпеки
Vibe Coding, новий тренд у розробці ПЗ, дозволяє створювати програми за допомогою ШІ-асистентів на основі простих запитів. Хоча це прискорює та спрощує процес, експерти з кібербезпеки попереджають про серйозні ризики, такі як вразливості в коді, витік даних та тіньова розробка.

Databricks Genie: Новий Рівень Агентів Даних для Корпоративних Завдань
Databricks представила Genie, передового агента даних, що значно покращує точність відповідей на складні запитання про корпоративні дані. Завдяки унікальним технікам, таким як спеціалізований пошук знань, паралельне мислення та архітектура Multi-LLM, Genie демонструє ефективність понад 90% у реальних сценаріях, долаючи виклики динамічних систем даних.