
Databricks Genie: Передовий Агент для Корпоративних Даних
Databricks представила Genie, сучасного агента даних, розробленого для відповіді на складні запитання щодо корпоративних даних. Ці дані включають як структуровані джерела (таблиці, дашборди, ноутбуки), так і неструктуровані (файли робочого простору, Google Drive, Sharepoint). Genie використовує унікальні техніки для вирішення викликів, притаманних агентам даних.
Виклики для Агентів Даних у Порівнянні з Агентами Кодування
Агенти кодування ефективно працюють у статичних, детермінованих середовищах, таких як файлова система диска. Натомість, агенти даних функціонують у динамічному, постійно еволюціонуючому озері даних (data lakehouse), що містить великий обсяг семантичного контексту з сотень тисяч таблиць, ноутбуків, дашбордів та документів.
Наприклад, внутрішній користувач може помітити суперечливі піки в звітах про дохід одного й того ж продукту на різні дати та попросити агента пояснити причину. Це питання є складним, оскільки жодне окреме джерело даних не містить відповіді. Для його вирішення потрібне міжсистемне виявлення даних у таблицях, внутрішніх документах та дашбордах, а також міркування про налаштування багатоденних звітів. Крім того, агент має заглибитися в деталі корпоративного ціноутворення для пошуку договірних ставок та автоматично коригувати себе, коли проміжні розрахунки виявляють неправильні початкові припущення. Genie успішно вирішує такі завдання, проходячи фази: паралельне багатоагентне виявлення даних, дослідження даних, цикл самокорекції та верифікація.
Три ключові унікальні виклики для агентів даних порівняно з агентами кодування:
- Масштаб виявлення даних: Пошук правильних джерел даних для відповіді на запит користувача є одним з найбільших викликів, оскільки корпоративні клієнти мають мільйони структурованих та неструктурованих джерел, що руйнує традиційні методи пошуку.
- Визначення "джерела істини" бізнес-знань: Відповіді на бізнес-питання потребують глибоких, специфічних знань з багатьох джерел (наприклад, метадані таблиць, документи компанії, внутрішні повідомлення), які часто є застарілими, суперечливими або заміненими, що змушує агента визначати найбільш авторитетну інформацію.
- Відсутність перевірених тестів: На відміну від агентів кодування, які можуть використовувати детерміновані, перевірені тести для ітеративного вдосконалення коду, агенти даних не мають відповідних тестів, оскільки "специфікація" є лише високорівневим запитом користувача без поняття очікуваної правильної відповіді. Крім того, запити не завжди можуть бути вирішені через неповноту даних, і важливо, щоб агенти даних могли ідентифікувати такі випадки та повідомляти про них користувачам.
Технічні Інновації Genie
Genie включає кілька ключових технічних інновацій, які дозволяють йому працювати значно краще, ніж звичайні агенти кодування:
Спеціалізований Пошук Знань (Specialized Knowledge Search)
Ця техніка використовує існуючі активи даних, такі як таблиці робочого простору, ноутбуки, дашборди, документи та файли, для отримання багатого семантичного корпоративного контексту. Потім цей контекст використовується для побудови пошукового індексу. Genie застосовує кілька пошукових індексів паралельно разом з багатими метаданими для ефективного виявлення найбільш релевантних активів для запиту користувача. Завдяки цьому Genie покращує продуктивність пошуку таблиць до 40% у внутрішніх бенчмарках.
Паралельне Мислення (Parallel Thinking)
На відміну від завдань програмної інженерії, де агенти кодування можуть спочатку написати тести для перевірки бажаної функціональності, а потім ітерувати генерацію коду, поки тести не пройдуть, відкриті запити даних не мають таких відповідних модульних тестів. Щоб вирішити цю проблему, Genie використовує паралельне мислення, вибірково генеруючи кілька траєкторій та агрегуючи відповідну інформацію з них для обчислення остаточної відповіді. Це значно покращує точність відповіді, хоча і з деякими додатковими витратами на затримку та токени. Комбінування цієї техніки з Multi-LLM та подальшими оптимізаціями може значно зменшити витрати та затримку.
Архітектура Multi-LLM
Однією з ключових технічних переваг Genie є можливість використовувати різні великі мовні моделі (LLM) для різних субагентів, оскільки різні LLM добре справляються з комплементарними можливостями. Наприклад, можна використовувати одну LLM для етапу планування, іншу для різних субагентів пошуку, ще одну для генерації коду та суддів. Платформа Databricks дозволяє безперешкодно випробовувати будь-які передові моделі (включаючи Opus, GPT та Gemini), моделі з відкритим вихідним кодом, а також спеціально навчені моделі. Спостерігається, що різні LLM також призводять до дуже різних характеристик затримки та вартості, які можуть бути оптимізовані за допомогою методів, таких як GEPA.
Результати та Висновок
Завдяки цим технікам, Genie значно покращує загальну точність у внутрішньому бенчмарку реальних завдань аналізу даних, збільшуючи її з 32% до понад 90% порівняно з провідним агентом кодування. При цьому також значно знижуються витрати та затримка. Хоча кодування та аналіз даних мають багато концептуальних подібностей, динамічна природа корпоративних систем даних створює унікальні виклики. Genie ефективно виявляє потрібні активи з великого корпоративного контексту, визначає "істину" в неоднозначному середовищі та генерує ефективний код і запити для правильної відповіді на запитання користувачів.
Що це означає для розробників
Genie дозволяє розробникам ефективніше працювати зі складними корпоративними даними, автоматизуючи виявлення джерел, визначення "джерела істини" та самокорекцію. Це значно спрощує аналіз даних, зменшуючи потребу в ручному пошуку та верифікації, а також підвищує точність відповідей на запити.
Ключові факти
-
Genie — це передовий агент даних від Databricks для складних запитань про корпоративні дані.
-
Він працює зі структурованими та неструктурованими джерелами даних.
-
Genie покращує точність з 32% до понад 90% порівняно з провідним агентом кодування.
-
Ключові техніки Genie: спеціалізований пошук знань, паралельне мислення та архітектура Multi-LLM.
-
Агенти даних стикаються з викликами масштабу виявлення даних, визначення "джерела істини" та відсутності перевірених тестів.
Джерела
Джерело
DatabricksThe Databricks AI Research Team
Pushing the Frontier for Data Agents with Genie8 травня 2026
Попередні статті

Vibe Coding: Революція у розробці та нові виклики для кібербезпеки
Vibe Coding, новий тренд у розробці ПЗ, дозволяє створювати програми за допомогою ШІ-асистентів на основі простих запитів. Хоча це прискорює та спрощує процес, експерти з кібербезпеки попереджають про серйозні ризики, такі як вразливості в коді, витік даних та тіньова розробка.

BigID розширює DSPM на файли Markdown, усуваючи критичний пробіл у безпеці даних
BigID оголосила про підтримку сканування та класифікації файлів Markdown (.md), ставши єдиним рішенням DSPM, здатним виявляти та захищати конфіденційні дані в інструкціях для ШІ, які є невидимими для традиційних інструментів безпеки.
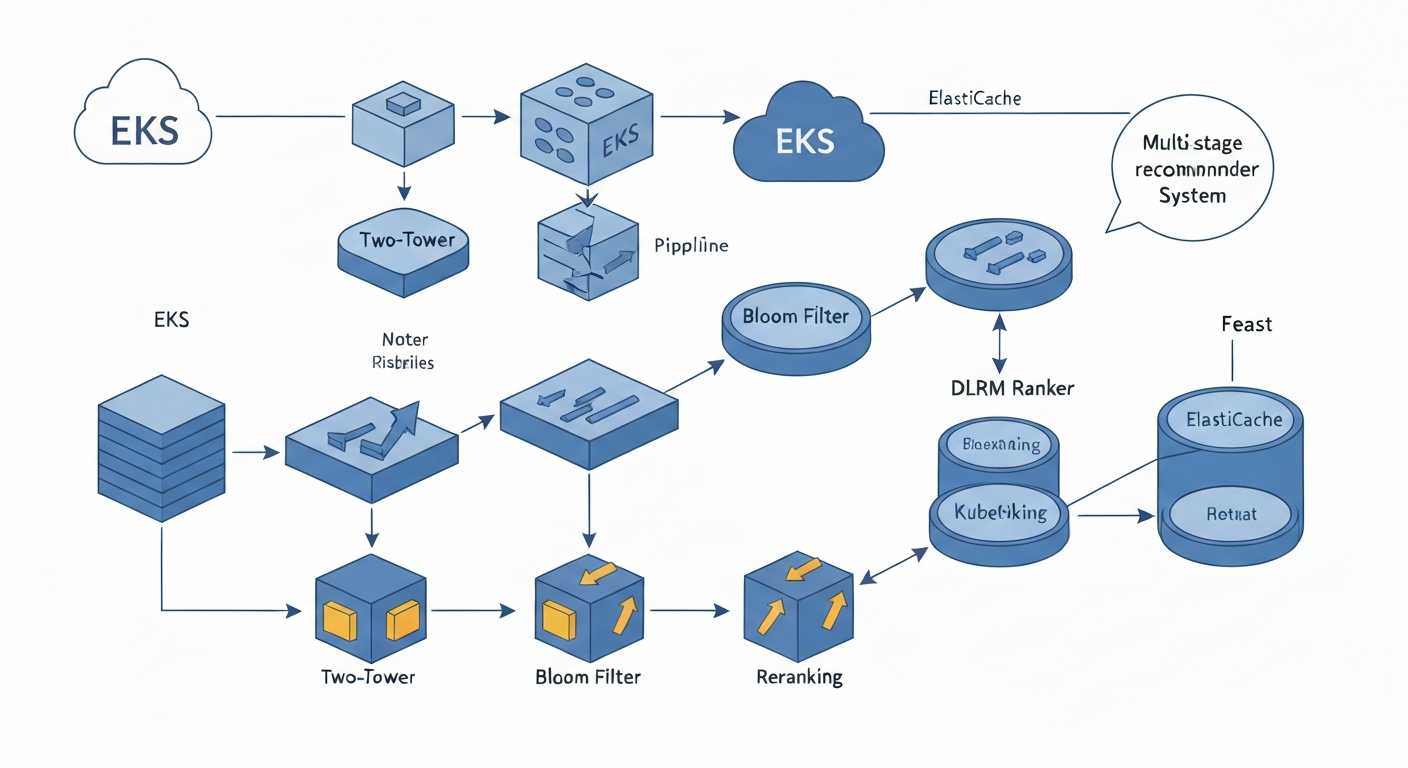
Розгортання багатоетапної мультимодальної рекомендаційної системи на Amazon EKS
Огляд архітектури та розгортання багатоетапної мультимодальної рекомендаційної системи на Amazon EKS, що поєднує Two-Tower пошук кандидатів, контекстно-орієнтоване ранжування DLRM та оптимізації для масштабованості, адаптації в реальному часі та обробки холодного старту.
Наступні статті

Мислити як дата-сайєнтист без кодування: Погляд Джастіна Еванса
Джастін Еванс, ветеран індустрії даних, у своїй новій книзі стверджує, що для успіху в економіці, заснованій на даних, не потрібні глибокі технічні знання. Достатньо комп'ютерної грамотності та вміння ставити правильні питання.

Хмарні Обчислення: Ринок Зростає до $2.9 Трильйона до 2034 року Завдяки ШІ та Гібридним Рішенням
Глобальний ринок хмарних обчислень, оцінений у $781.27 млрд у 2025 році, прогнозується зрости до $2.9 трлн до 2034 року зі щорічним зростанням 15.7%. Основними рушіями є цифрова трансформація підприємств, інтеграція штучного інтелекту, гібридні інфраструктури та інвестиції в гіпермасштабні платформи.

Дівчата в ЄС демонструють високі цифрові навички, але відстають у кодуванні
Згідно з даними Eurostat за 2025 рік, дівчата віком 16-19 років у ЄС перевершують середній показник населення за рівнем навичок створення цифрового контенту, проте значно відстають від хлопців у програмуванні.